


How many times have you encountered a problem and thought "God, how to do this??". Well not that this is that kind, but yes it took a novice like me to dig deep into to get a solution.
In the world of NLP and Web Scraping, we all have this dilemma thinking how to extract a piece of text or a pdf file or a piece of image from a website, that too when your client says "we need the code to start from the very first page". Hmmmm!! I bet all of the experts must have faced this quite many times. But the fact for us, newbies, to understand is that, we need to give solutions that are end-to-end, and, not just extract the page/ image/ text from the end page and hand it. As they say there is no easy way out!!!!
Well enough of philosophy for all, let's dig into the problem I had in hand and see the solution to it. Our client had a peculiar job in hand, to extract a piece of latest judgement being passed in the Supreme Court and save it as PDF. Seems like fun isn't it??
Firstly we understand what is Web Scraping?
Web scraping is a technique for extracting information from the internet automatically using a software that simulates human web surfing. In our case we use the power of Python to do the job for us, while we configure the code.
Under the hood we will use the following:
a. Python 3.0: We will use Python 3.0 for our coding. You are free to use as per your requirement with some adjustments.
b. IDE of your choice: We will be using Jupyter notebook.
c. Selenium package: You can install selenium package using "pip" or directly into the command prompt. In order to search the correct command you can go to the anaconda website and search for the appropriate command to use for installing a package.
d. Chrome Driver: We would need to install Google Chrome in the system for us to work on it. You can use any other driver, but for me it felt easier and comfortable to use chrome driver. Please install the chrome driver from here
Now getting to the main part we first need to import the necessary libraries:
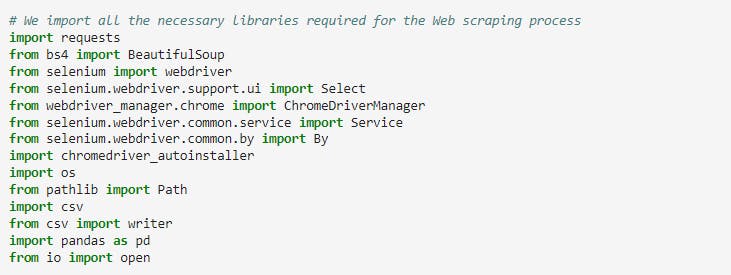
We now define custom functions for the step by step procedure of the web scraping. Starting with defining the base url website "IndianKanoon.org" and forming a template for the supreme court judgements to be scraped.

Website Layout
Next in line, we need to get to the next page, under this page we have options for the year pertaining to which we need to choose from.
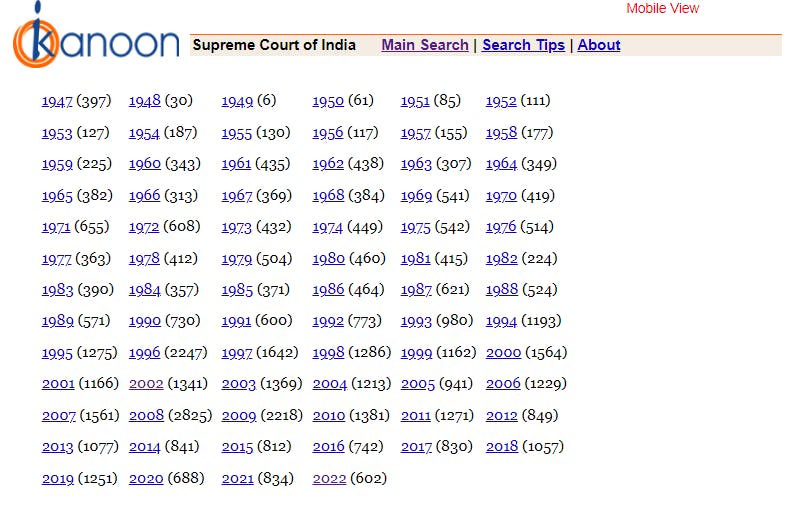
In order to do so we define a function for opening the page of the corresponding year we select to input under the defined function, when it is called upon.
Inspect HTML/XML script on a website
In order to do so we use BS4 and extract the element which corresponds to the years in the page. For ones who are new to this we need to right click on the page and select inspect.
Further on a window opens with the full html script of the page.
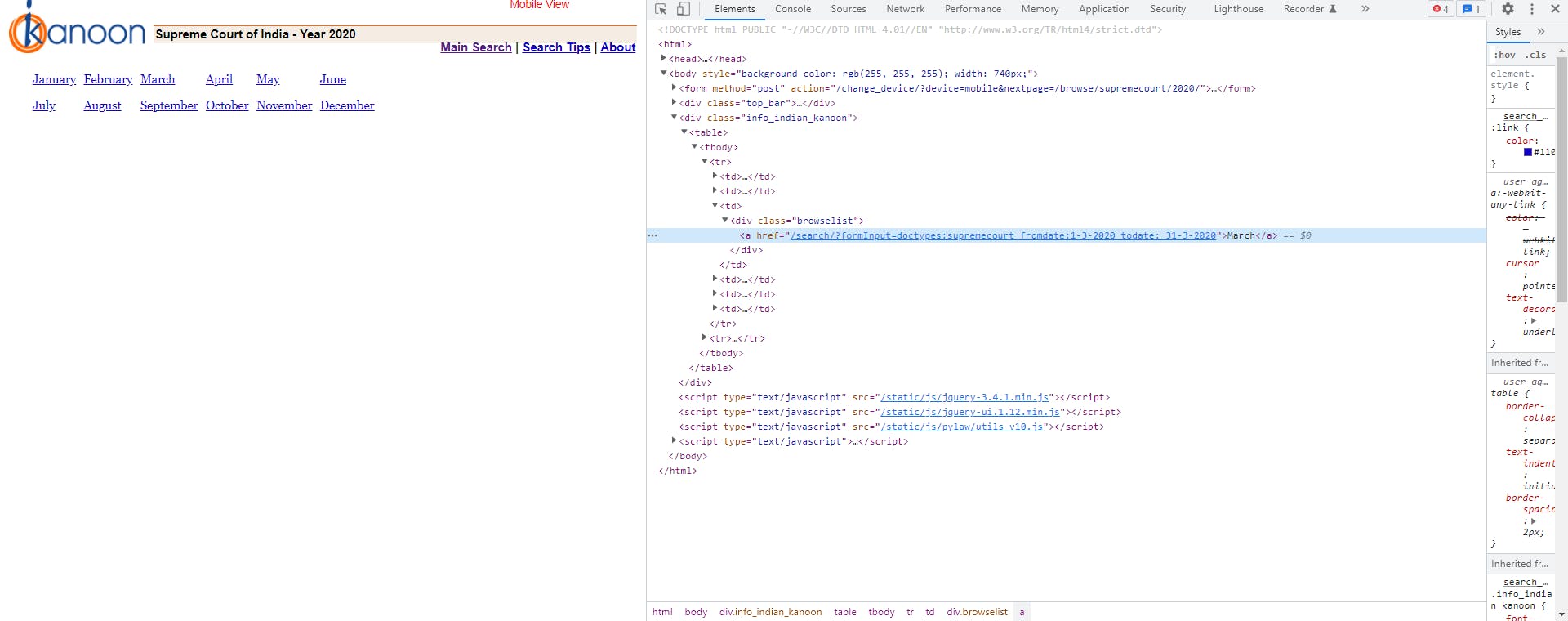
Using this for the year element we choose the 'href' option to get the link for the particular year.

Similarly again we use the same theory to get a link for the next page which defines the month we need to choose and extract/ reach to the same.
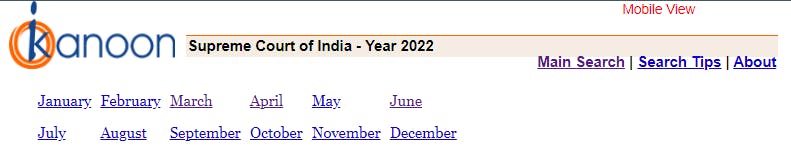
And write the same piece of code with the elements for the month to be extracted from the html script. Additionally once we reach the page we see a dropdown bar that needs to be selected to show the most recent entries. Which in turn will be used to get to the latest judgement call. Now I happened to take a call and defined the link url to have the "sort by most recent one", which seemed to be an easy part.

Now that we have come to the page with the latest entries, we need to go to the latest entry that will lead to the judgement page ("like quite obviously"), from where we shall extract the pdf file.
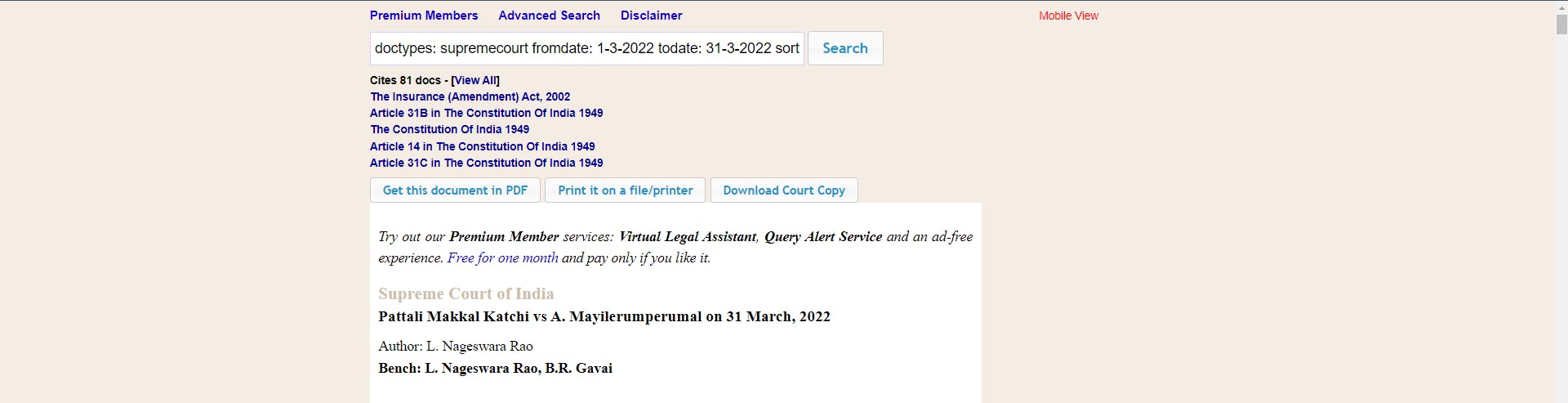
The Dilemma
Then came the part where I got lost into the vicious circle of searching the right path to extract the pdf file. As while inspecting into the html script, it was only leading to opening a blank page and no way to extract the same. Then I came across the way out by using the "find_elements_by_xpath" under Selenium. So my research not only lead me to learn the new fact but helped me to solve the issue as well. Hence always remember to search-research-learn-solve-repeat.
In this last piece of code under the whole project I happened to define a function that shall use the Xpath for button "Get this document in PDF" and helps download the file as a final step under the hood.
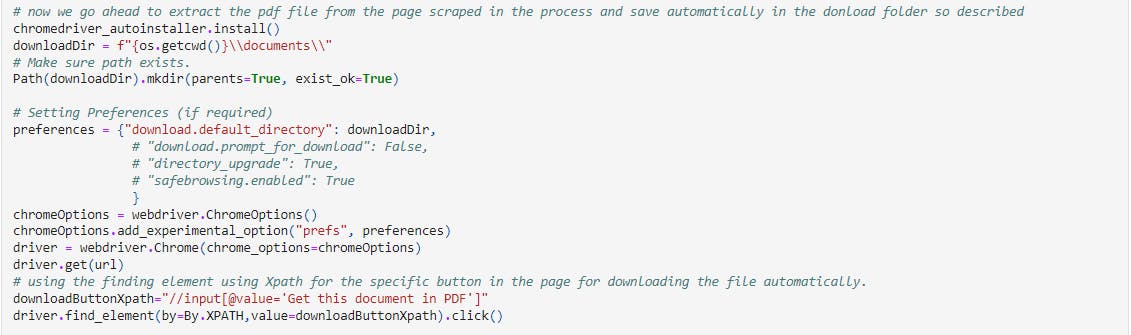
Summary
To sum it up we learned what Web scraping is, what libraries to be used, what is inspect, how to try and code for the next pages and how to use selenium to extract using find elements.
We can further use the pdf to extract the text and use for various purposes like sentiment analysis, NER, Topic modelling, etc., etc. and list would continue, but let's keep that discussion and learning for some other day.
Feel happy to visit my code and suggest improvements.
Also please feel free to visit a post on Web scraping by Mr. Atindra Bandi, which helped me to solve the issues with the XPath and learn further on.
Keep Learning!!!!!!!!!!!